




系列导读:流媒体时代,内容供给的无限性与用户注意力的有限性构成了核心矛盾。为应对“选择过载”的挑战,一种旨在为每位用户创建专属内容流的“超级个性化频道”范式应运而生。其背后是机器学习,尤其是大语言模型(LLM)的技术突破。本系列将分三部分,系统性地解析这一前沿趋势。本文为第一篇,聚焦于构建个性化频道所需的核心算法框架。
关联阅读:
个性化频道的“最后一公里”:触点整合如何重塑用户内容消费范式
引言:从“人找内容”到“内容找人”的范式革命
个性化推荐系统的发展,是一部不断向“理解用户”这一终极目标逼近的历史。早期的协同过滤(Collaborative Filtering) 算法,核心思想是“物以类聚,人以群分”,通过寻找与你品味相似的用户,将其喜欢而你未看过的东西推荐给你。这一方法在商业应用中首次证明了个性化推荐的巨大价值,但其理论基础也决定了它难以克服的缺陷:严重的数据稀疏性(在数百万用户与作品的交互矩阵中,绝大部分位置是空白的)和冷启动问题(新用户或新作品因缺少交互数据而无法被有效推荐)。
为解决这些问题,以矩阵分解(Matrix Factorization) 为代表的潜因子模型在著名的Netflix Prize百万美元大赛中大放异彩。它不再依赖于寻找相似的“邻居”,而是试图为每个用户和作品学习一个低维的、稠密的“潜藏特征向量”(Latent Factor Vector)。这正是“向量化表示”思想的雏形,它将推荐从基于显式行为的匹配,带入了基于隐式特征的预测时代,极大地提升了模型的泛化能力。
进入深度学习时代后,推荐系统迎来了又一次飞跃。强大的非线性建模能力使得模型可以轻易融合文本、图像、音频以及丰富的用户上下文特征,从而获得前所未有的表达力。而当前,以GPT、Llama为代表的大语言模型(LLM)正引发新一轮的范式革命。据不完全统计,主流视频平台的媒资库已达数百万小时,每日新增内容数以万计,这使得人工编辑推荐的模式难以为继。LLM不仅是强大的特征提取器,其涌现出的世界知识、逻辑推理和指令遵循能力,使其有望成为推荐系统的“决策大脑”,从根本上改变内容的分发与编排逻辑。本文将深入剖析在这一背景下,构建超级个性化频道所需的核心算法框架。
图-1 显示了行业经典的两阶段内容推荐的架构,YouTube 两阶段推荐架构(候选生成→精排)
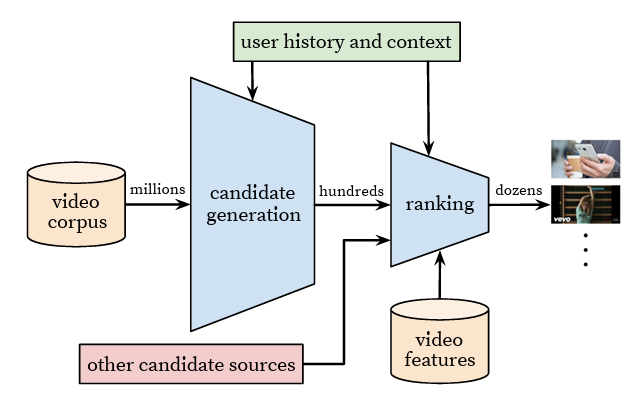
图-1:行业经典两阶段推荐架构(YouTube,Covington et al., RecSys’16)
一、 向量化表示:深度理解用户与内容的基石
向量化表示(Vector Representation),或称嵌入(Embedding),是现代推荐系统的技术基石。其目标是将现实世界中离散、高维的各种信息(用户ID、作品ID、文本、图像),映射到低维、稠密的连续向量空间中,从而让计算机能够理解和计算它们之间的复杂关系,是实现“千人千面”的先决条件。
1.1 架构演进:从单塔到双塔
在深度学习推荐模型中,经典的“双塔模型(Two-Tower Model)”架构是实现向量化表示的主流选择。它包含两个独立的神经网络(塔),在训练时分别负责处理用户和作品的特征,而在服务时则实现了高效的解耦:
· 用户塔(User Tower):输入用户的静态特征(如年龄、地理位置)、动态行为序列(观看历史、搜索记录、点击偏好)以及上下文特征(时间、设备),通过多层神经网络(DNN)的处理,最终输出一个代表该用户在当前状态下兴趣的“用户向量”。这个计算过程是实时的,在用户每次请求时动态生成。
· 作品塔(Item Tower):输入作品的元数据(如标题、导演、演员、类型)、内容特征(如剧情简介、封面图像、用户评论),同样通过一个独立的DNN,输出代表该作品属性的“作品向量”。由于作品的特征相对固定,作品塔可以在离线环境中完成计算,将数百万甚至上亿的作品向量提前生成,并构建索引。
训练时,模型的目标是让正样本(用户实际交互过的作品)的用户向量与作品向量在空间中尽可能接近(如余弦相似度更高),而让负样本(用户未交互或不喜欢的作品)的向量对尽可能远离。这种架构的巨大优势在于,它将复杂的深度模型匹配问题,巧妙地转化为了向量空间中的相似度检索问题。在线服务时,系统无需对海量作品进行逐一打分,只需拿着实时生成的用户向量,到预先建立好的作品向量索引库中进行高效的近似最近邻(ANN)搜索,即可在毫秒级时间内召回最匹配的数百个候选作品,完美解决了在线服务的低延迟要求。
1.2 多模态信息的深度融合
为了构建信息量更丰富的向量,平台正致力于融合更多模态的数据,以期获得对用户和内容更全面的认知:
· 文本语义理解:利用预训练的自然语言处理模型(如BERT、RoBERTa)对内容的标题、剧情简介、用户评论进行编码,可以捕捉到比关键词更深层次的语义信息。例如,模型能理解“黑色幽默”与“讽刺喜剧”之间的关联,或识别出一部电影复杂的情感基调,甚至能从用户评论中挖掘出关于“配乐出色”或“节奏拖沓”的观点性特征。
· 视觉风格分析:通过卷积神经网络(CNN)或更先进的Vision Transformer模型,分析电影海报、剧照或视频关键帧,可以提取出画面的色彩、构图、光影等视觉风格特征。这对于匹配用户在视觉美学上的偏好至关重要,例如,一个偏爱韦斯·安德森式对称构图的用户,可能会被推荐具有相似视觉语言的冷门电影。
· 音频特征提取:对于视频内容,其配乐、音效、人声语调等音频特征同样蕴含丰富信息。通过对音频轨道进行分析,可以识别出是快节奏的动作场面还是舒缓的对话场景,从而更精准地匹配用户在不同情境下的观看需求。例如,在深夜时段为用户推荐音景(Soundscape)更柔和的内容。
将这些从不同模态提取的特征向量进行拼接或通过更复杂的注意力机制(Attention Mechanism)进行加权融合,最终生成的统一向量表示,将前所未有地逼近对一个内容产品的“完整刻画”。
二、 强化学习与大模型驱动的排片机制
如果说向量化解决了“找到什么”的问题,频道编排则要解决“如何呈现”这一更复杂的动态决策问题。这需要算法具备长远眼光,在保证用户即时满足感的同时,最大化其长期留存与价值。强化学习(RL)为此提供了理想的理论框架。
2.1 强化学习:赋予推荐系统“长远眼光”
在推荐场景中,强化学习的核心要素可以被定义为:
- 智能体(Agent):推荐系统本身。
- 环境(Environment):用户以及他所处的整个平台界面。
- 状态(State):用户当前的画像、历史行为、所处的时间、正在浏览的页面等。 动作(Action):向用户推荐一个或一个系列的内容。
- 奖励(Reward):用户的反馈,这是最关键也最难定义的一环。简单的奖励可以是“用户是否点击”,但这容易导致“标题党”内容泛滥。更优的设计应是复合的长期奖励,例如将“观看时长”、“完播率”、“点赞”、“分享”等多个指标加权,甚至引入“下次访问时间间隔”、“是否完成续费”等延迟奖励信号,以引导模型学习能带来长期价值的策略。
通过不断的“动作-奖励”循环,RL智能体学习到一个最优策略(Policy),即在何种状态下应该执行何种动作,才能获得最大的长期累积奖励。这使得推荐不再是短视的“唯点击率论”,而是着眼于用户生命周期总价值的战略性决策。
2.2 从理论到实践:上下文多臂赌博机
完整的强化学习(如Q-Learning、DDPG)在真实推荐系统中的应用仍面临样本需求量大、训练不稳定、以及线下评估困难等挑战。因此,一种更轻量、更实用的RL变体——上下文多臂赌博机(Contextual Bandit) 被广泛应用。
Bandit算法将每次推荐视为一次“拉动老虎机摇臂”的尝试,不同之处在于它会利用“上下文信息”(即用户和作品的特征向量)来辅助决策,从而更快地找到每个用户专属的“最优摇臂”。Netflix利用它进行封面个性化,就是典型的成功案例。Bandit算法的优势在于其高效的在线学习能力,能快速响应用户兴趣的变化,并有效平衡“探索与利用”的窘境,在不过多牺牲用户短期体验的前提下,持续为用户带来新鲜感。
2.3 LLM:从“语义理解”到“决策规划”
大语言模型的加入,正将排片机制推向新的高度。其角色已远不止于丰富内容理解:
· 作为零/少样本推荐器:对于冷启动的作品,LLM可以仅凭其文本描述,就利用自身庞大的世界知识推断出其潜在的目标用户群体,无需任何交互数据。这对于新内容的快速分发具有不可估量的价值。
· 作为决策规划器:LLM强大的逻辑推理能力使其可以直接参与编排。例如,可以向LLM输入一个包含用户画像、近期行为和业务目标的复杂Prompt,要求它直接生成一个兼顾用户兴趣、内容多样性和平台导向的、带有详细解释的播放列表。这相当于将传统的、由多个子模型构成的复杂推荐流程,统一到一个端到端的、可解释的生成模型中。当然,将LLM作为端到端的决策大脑,目前仍面临着推理成本高昂、事实一致性难以保证、以及如何与强化学习框架有效结合等诸多挑战,是学术界与工业界共同关注的前沿课题。
三、 代表性案例与成效分析
图-2:Netflix TV 端首页示例 来源:The Verge(2025-05-07 报道)。
· Netflix:作为深度个性化的先驱,其成功不仅在于算法本身,更在于建立了一套以A/B测试为核心的,快速迭代、数据驱动的文化。任何微小的改动,从推荐算法的调整到UI按钮颜色的变化,都必须经过严格的在线对照实验,以量化其对核心指标(如用户留存、观看时长)的影响。其著名的“影片封面个性化”项目,通过Bandit算法为不同用户展示不同风格的封面,就带来了显著的观看率提升。这种将个性化渗透到产品每个毛细血管的策略,共同构筑了其强大的用户粘性壁垒。
· Spotify:其推出的AI DJ功能是“LLM+推荐”的标杆性应用。其技术栈清晰地展示了人机协同的未来:1)个性化算法:核心的推荐系统,负责挑选出符合用户长期和短期兴趣的歌曲序列。2)生成式AI:由大语言模型构成的“编剧”,它获取歌曲信息和用户听歌历史,实时撰写出自然、流畅且富有洞察力的解说词。3.)声音合成技术:通过授权和克隆一位知名电台主播的声音,生成高度逼真且带有情感的语音播报。这三者的结合,将一个简单的播放列表,升维成了一场有灵魂、有陪伴感的沉浸式体验,极大地提升了用户探索新音乐的意愿。

图-3:Spotify AI DJ 在移动端的 UI 来源:Spotify Newsroom(2023-02-22)。
这些案例可以证明,算法框架的升级 — 从向量化深刻描绘偏好,到强化学习智能规划序列,再到大模型增强理解与生成 — 共同构成了超级个性化频道坚实的技术基础,并能直接转化为可量化的用户留存(粘性率)和商业收益。
(未完待续)
推荐阅读:
责任编辑:凌美
24小时热文
流 • 视界









专栏文章更多
- [金博士] 从算法到生态:超级个性化频道的终极实践指南 2025-10-10
- [金博士] 个性化频道的“最后一公里”:触点整合如何重塑用户内容消费范式 2025-10-10
- [金博士] 千人千面进阶史:解码Netflix/Spotify背后的个性化算法战争 2025-10-10
- [常话短说] 【解局】广电人这波操作,杠杠的! 2025-10-10
- [探显家] Amazon为Fire TV打造新Linux系统「Vega」,告别Android时代 2025-10-10